如何应用AndesCore™ EDM 安全访问机制
沈永胜,技术副哩,晶心科技股份有限公司
EDM 安全存取是 AndesCoreTM 内建的功能(option),应用在安全存取的控管。EDM 安全存取有二种的控管方式:debug access indication 和 EDM access restriction。第一种控管方式(debug access indication)提供了一个 sideband signal 用于指示从调试器(Debug host)的请求。第二种控管方式, 控制AndesCoreTM 的 input port(edm_restrict_access )达到 EDM 存取的限制。更详细的内容在后续章节会有更深入的介绍。
1. EDM功能介绍
一个 debug system 包含一个 debug host 和一个 target system。EDM 主要的功能就是 translate debug host 发出的 TAP 指令來存取系统 memory 或是 CPU。图表 1 为基本的 debug 系统方块图:
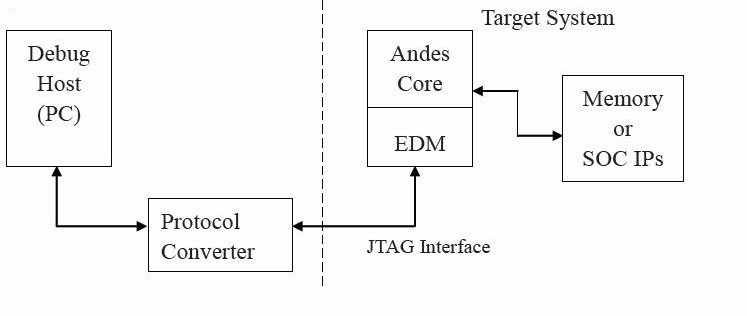
图表 1 基本的 debug 系统方块图
图表 2 說明 TAP 指令的种類:
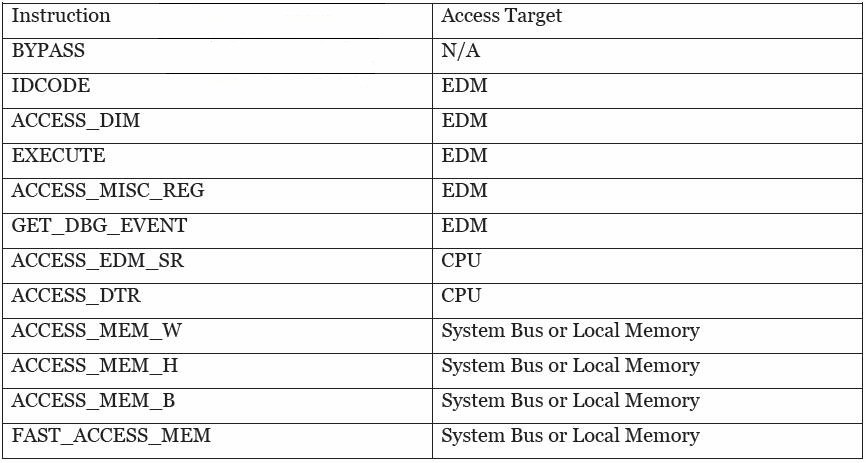
图表 2 TAP 指令的种類
2. 控制EDM存取的限制
使用 EDM 的访问方式会被一个 sideband signal (edm_restrict_access) 所影响。当这个 signal 值是 high,仅仅只能对 EDM MISC registers 做讀取的动作。而想要存取CPU/System Bus/Local Memory 的动作将会被封锁住并且会得到下面的结果:
- 讀为零写忽略
- 不正确的 JTAG instruction(JTAG ICE debugger 会 timeout)
图表 3 說明 EDM 限制存取方块:
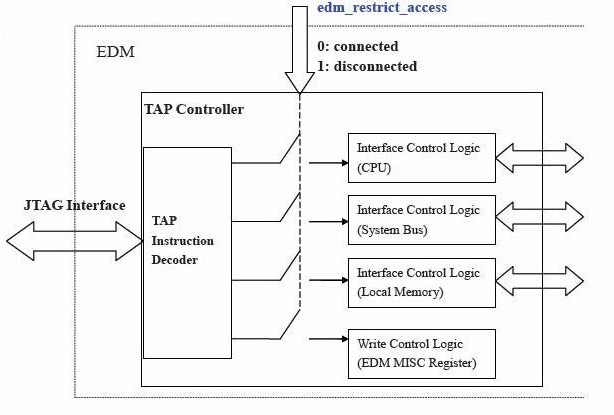
图表 3 EDM 限制存取方块图
在启用存取限制功能后,图表 4 說明出每个 TAP 指令的行为:
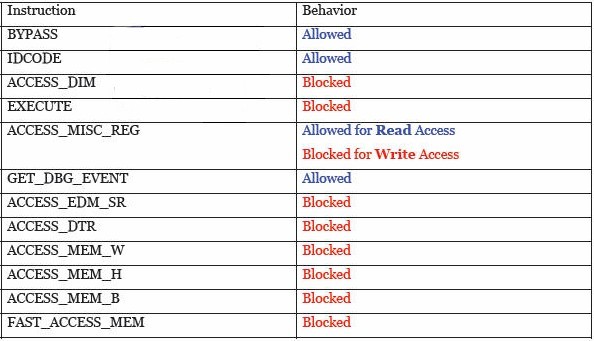
图表 4 TAP 指令的行为
如何实现 EDM 存取限制,在系统设计上有很多种实现方法,以控制 edm restrict access 的 signal。兩种基本的设计方案說明如下:
- eFUSE 方式使用 Chip 重新编程管理控制
- SOC 方式使用软件管理控制
图表 5 所示为 hardware 实现控制 edm_restrict_access 的示意图如下:
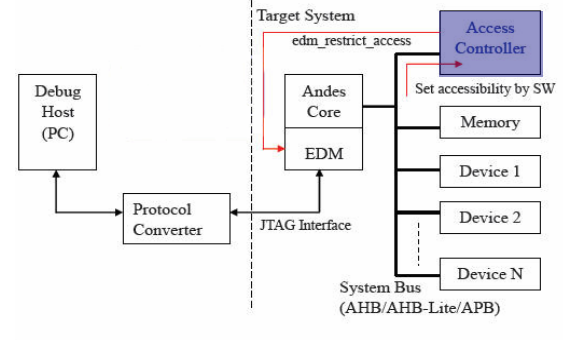
图表 5 Hardware 实现控制 edm_restrict_access 的示意图
software 实现控制 edm_restrict_access的例子如下:
- sethi $r2,#0x80000
- ori $r2,$r2,#0x8c
- sethi $r3,#0x04030
- ori $r3,$r3,#0x201
- swi $r3,[$r2+#0]
3. EDM 存取指示
AndesCoreTM 增加一个额外的 sideband signal,xdebug_access(active-high),根据此 sideband signal 來决定 request 的 host 是否为 EDM。而 device 就能根据此 sideband signal 决定是否要把 request 的 data 内容传回到host。
sideband signal 的名称根据 bus interface 的類型而有所不同。对于AndesCoreTM 处理器,基本的信号名称如下所示:
• AHB/AHB-Lite => hdebug_access
• APB => pdebug_access
• EILM => eilm_debug_access
• EDLM => edlm_debug_access
3.1. debug 存取識别信号控制
当 debug exception 发生后,CPU 将进入debug mode。然后 CPU 将会留在 debug access mode 直到CPU 执行到 IRET instruction 并且 trusted_debug_exit 是处于high 后CPU 将離开 debug access mode,反之 trusted_debug_exit 如果是low, CPU 将会保留在debug access mode。
实现控制 trusted_debug_exit 信号,有二种可供选择的方式如下:
• trusted_debug_exit 信号总是给 high
增加一个权限管理邏辑去控制trusted_debug_exit 信号是high 或是 low 权限管理邏辑方块图如图表 6 所示:
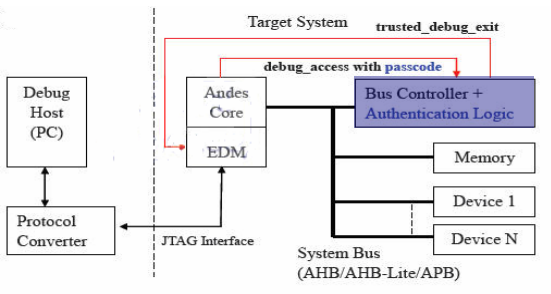
图表 6 权限管理邏辑方块图
如何控制 trusted_debug_exit 信号时序图如图表 7 所示:
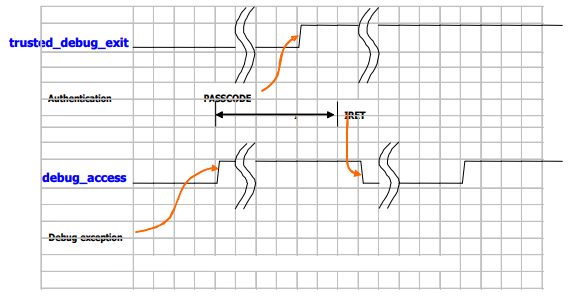
图表 7 如何控制 trusted_debug_exit 信号时序图
如下例子說明了如何产生 trusted_debug_exit 控制信号的verilog code:
- The code example (Verilog) of trusted_debug_exit generation is described below:
- //
- //— Utilize passcode to generate trusted_debug_exit in AHB Bus Controller
- //* assume zero-wait-state AHB access
- …
- parameter AUTH_CODE = 32’h0a0b0c0d;
- …
- always @(posedge hclk or negedge hreset_n) begin
- if (!hreset_n) begin
- passcode_reg <= 32’d0;
- end
- else if (passcode_wen) begin //debugger enters passcode through debug access
- passcode_reg <= hwdata[31:0];
- end
- end
- …
- //validate passcode to generate trusted_debug_exit
- assign trusted_debug_exit = (passcode_reg == AUTH_CODE);
3.2. debug 存取指示应用
图表 8 說明 AHB bus 如何使用 hdebug_access 和验证邏辑來防止惡意的 debug存取
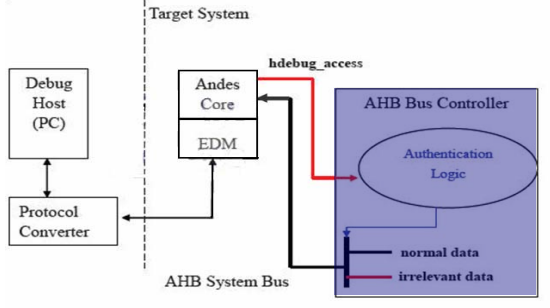
图表 8 AHB bus 如何使用hdebug_access 和验证邏辑來防止惡意的 debug 存取
如下 verilog code 說明了如何使用 hdebug_access 信号:
- //— Use hdebug_access to prevent malicious debug access in AHB Bus Controller
- //* assume zero-wait-state AHB access
- …
- parameter IRRELEVANT_DATA = 32’hcafe0001;
- parameter AUTH_CODE = 32’h01020304;
- …
- always @(posedge hclk or negedge hreset_n) begin
- if (!hreset_n) begin
- dbg_acc_d1 <= 1’b0;
- end
- else begin // data phase indication of debug access
- dbg_acc_d1 <= hdebug_access;
- end
- end
- …
- always @(posedge hclk or negedge hreset_n) begin
- if (!hreset_n) begin
- passcode_reg <= 32’d0;
- end
- else if (passcode_wen) begin //debugger enters passcode through debug access
- passcode_reg <= hwdata[31:0];
- end
- end
- …
- //validate passcode to check authentication
- assign auth_check_fail = (passcode_reg != AUTH_CODE);
- //return irrelevant data if the authentication check of debug access fails
- assign hrdata_out = {32{data_read_en}} &
- ((dbg_acc_d1 & auth_check_fail) ? IRRELEVANT_DATA : normal_data_out);
4. 实际的应用
使用者经由上面的介绍完成了权限管理邏辑后,并且挂在 AndesCoreTMAHB bus 上,再经由仿真器(Cadence)仿真此权限管理邏辑的行为,如下面几张图所示:
• edm_restrict_access 信号控制
图表 9 說明由 sw code 把 edm_restrict_access signal disable
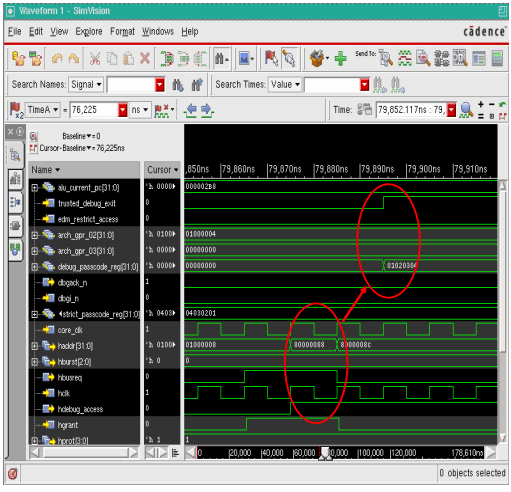
图表 9 由 sw code 把 edm_restrict_access signal disable
• trusted_debug_exit 信号控制
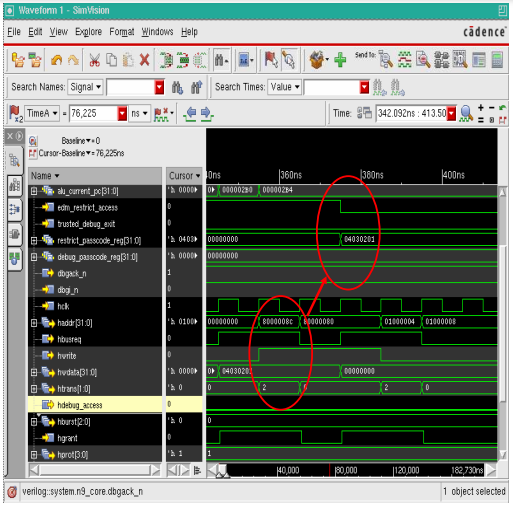
图表 10 经由 debug access 把 trusted_debug_exit signal 设定成high
• debug_access 信号
图表 11 說明经由 debug host 來做存取时,debug_access signal 会从 low 变成 high:
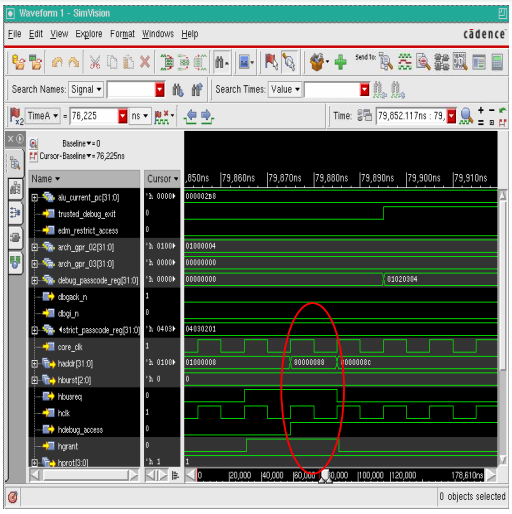
图表 11 经由 debug host 來做存取时,debug_access signal 会从 low 变成 high
图表 12 說明经由执行 IRTE instruction 时,debug_access signal 会从 high 变成 low:
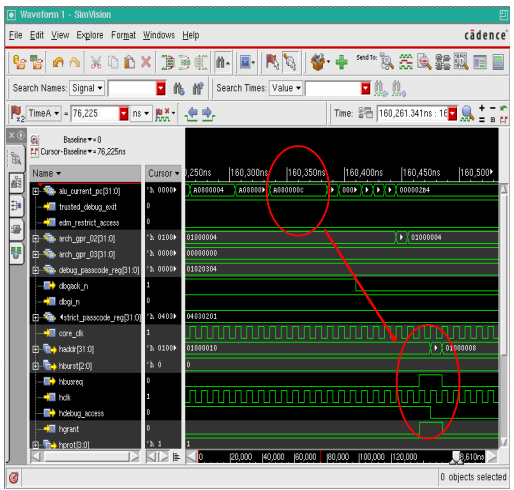
图表 12 经由执行 IRTE instruction 时,debug_access signal 会从high 变成 low
5. 结语
EDM 安全存取是 AndesCoreTM 保护周边装置内容不被窃取的功能,也因为越來越多客户使用到此功能,所以撰写此技术文章让客户更能进一步了解到此功能的用途,让客户能够很快速的上手,并且使用晶心开发的 EDM 安全存取是一件愉快与简单的工作。







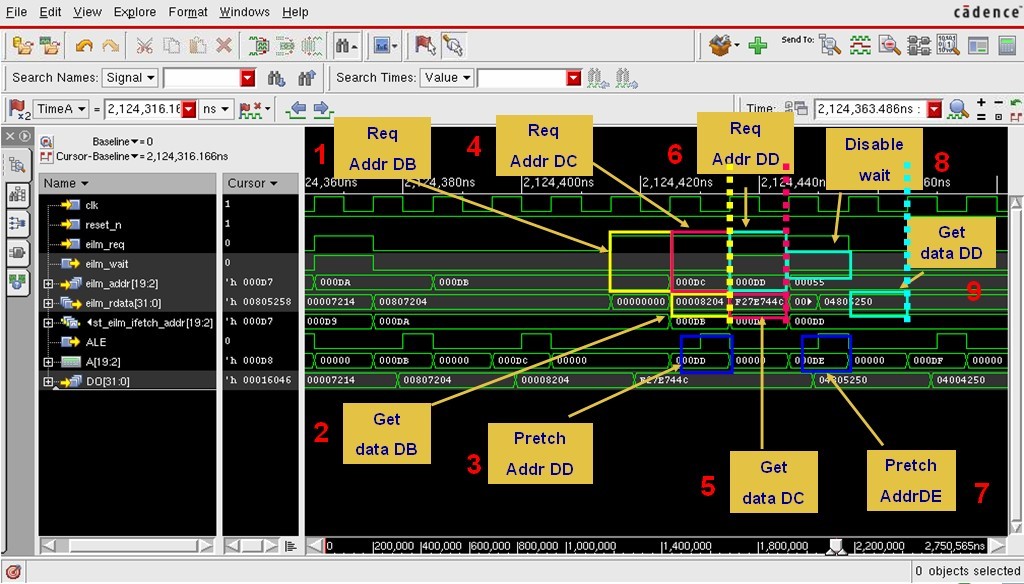

 图表1 主程序的 memory layout 图
图表1 主程序的 memory layout 图


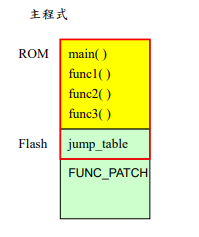
 图表2 ROM patch 的 memory layout 图
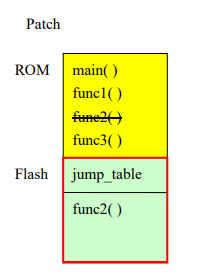
图表2 ROM patch 的 memory layout 图 图表 3 主程序的 symbol
图表 3 主程序的 symbol
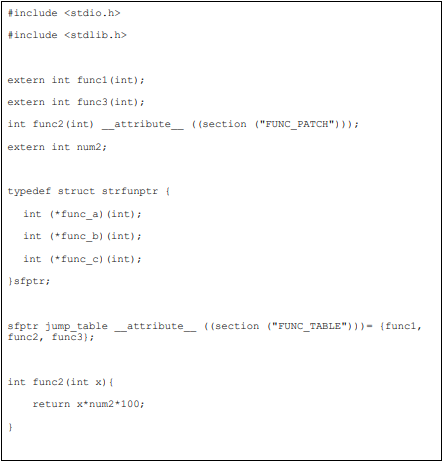

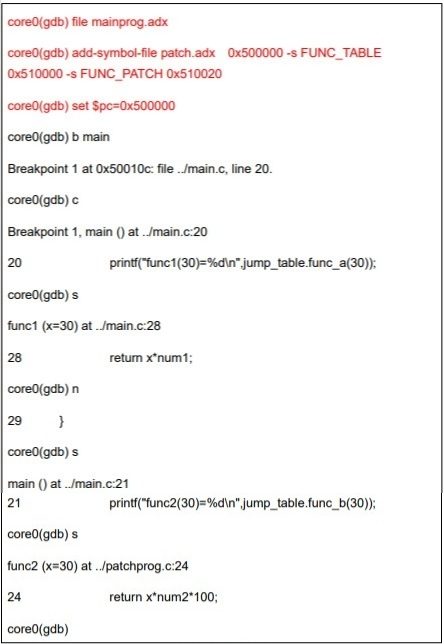

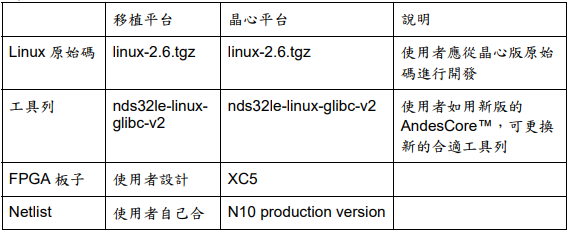







 SECTIONS 是 link script 语法中的关键 command,它用来描述输出文件的内存布局。例如上例中就含.text, .data, .bss 三个部分。
SECTIONS 是 link script 语法中的关键 command,它用来描述输出文件的内存布局。例如上例中就含.text, .data, .bss 三个部分。
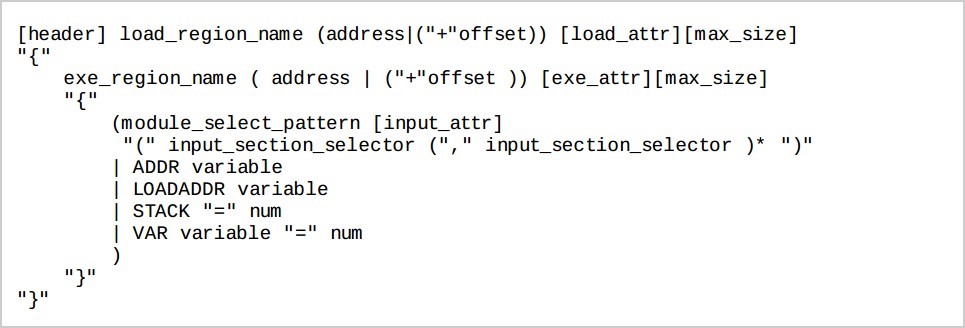
 当要使用用户自定义的 section 时,须要使用 USER_SECTIONS 这个关键字。
当要使用用户自定义的 section 时,须要使用 USER_SECTIONS 这个关键字。 load_region_name 用来表示某个程序加载区的名称。
load_region_name 用来表示某个程序加载区的名称。 exe_region_name 用于表示某个程序执行区的名称
exe_region_name 用于表示某个程序执行区的名称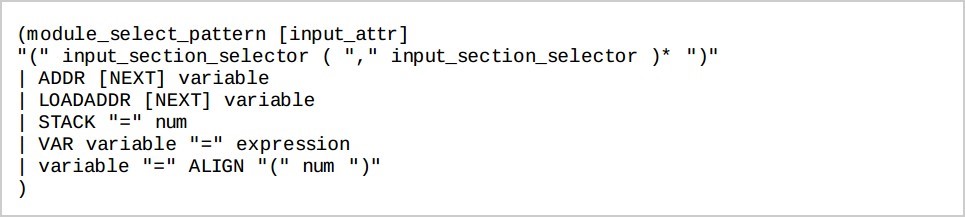 此处:
此处:
 它在后面加了个:OVERLAY 的关键字。
它在后面加了个:OVERLAY 的关键字。
 利用 SAG 机制,除了快速设计上列所示的系统中存储的分配机制,还可以快速的进行 overlay 程序的设计,overlay 程序主要是用于分时重复利用快速但存储空间有限的存储器。
利用 SAG 机制,除了快速设计上列所示的系统中存储的分配机制,还可以快速的进行 overlay 程序的设计,overlay 程序主要是用于分时重复利用快速但存储空间有限的存储器。